You Can't Hire Your Way Out of a Knowledge Problem
Srikanth Gaddam
CEO & Co-founder · May 18, 2026 · 7 min read
Every conversation with a support engineering leader eventually reaches the same sentence. "We need two more engineers. Otherwise we won't hit SLA."
The math is unarguable. Ticket volume rose with the last hundred customers. The team is already at capacity. SLA breaches mean churn risk. Procurement is faster than churn. Leadership approves the requisition.
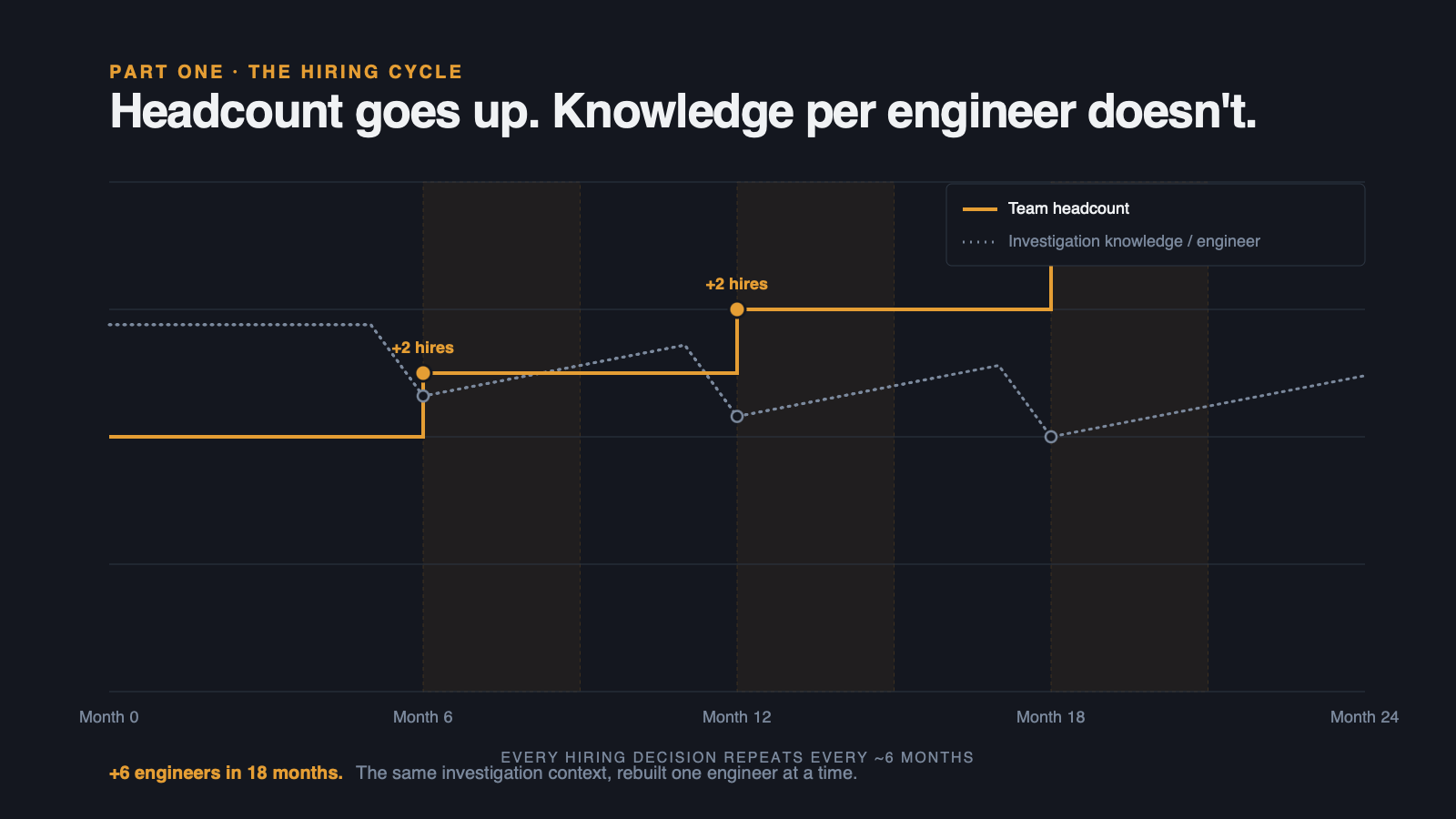
The new engineers join. Three months to ramp. Learning which services fail this way. Which logs to pull first. Which fixes hold and which only seem to. The same context the existing team accumulated over years, rebuilt one engineer at a time.
Six months later, another hundred customers. The same request goes in.
This is the most common scaling pattern in B2B support engineering. It is also the most expensive. The team scales linearly with ticket volume. The knowledge that makes investigation fast does not transfer with the headcount.
The headcount answer to a knowledge problem

Most enterprises treat support capacity as a staffing problem. Ticket volume divided by tickets-per-engineer-per-day equals required headcount. Add a buffer. Run the recruiting pipeline. Hit the number.
The model is wrong in a specific way. It assumes engineers are interchangeable units of investigation capacity. They are not. Roughly 70% of every support ticket's resolution time goes to investigation. The remaining 30% is the actual fix. This split has been measured independently across multiple enterprise teams, including BuildWright's design partners. Stripe's Developer Coefficient found engineers spend 42% of their total time on maintenance and debugging. That is the single largest category of engineering effort. An engineering manager who tracked their team on r/EngineeringManagers found only 15 of 48 minutes in mean time to resolution was actual debugging. The other 33 minutes were context gathering.
The investigation phase is where knowledge matters most. Which dashboard has the right service. Which database table holds the customer's reconciliation state. Which engineer fixed something similar in March. Which deployment changed the failing code path. None of this lives in the codebase. It lives in the heads of the engineers who have been there long enough to have seen it before.
When you add headcount to absorb rising ticket volume, you are adding investigation capacity. You are not adding investigation knowledge. The knowledge has to be rebuilt, one engineer at a time, every time.
What the ramp actually costs
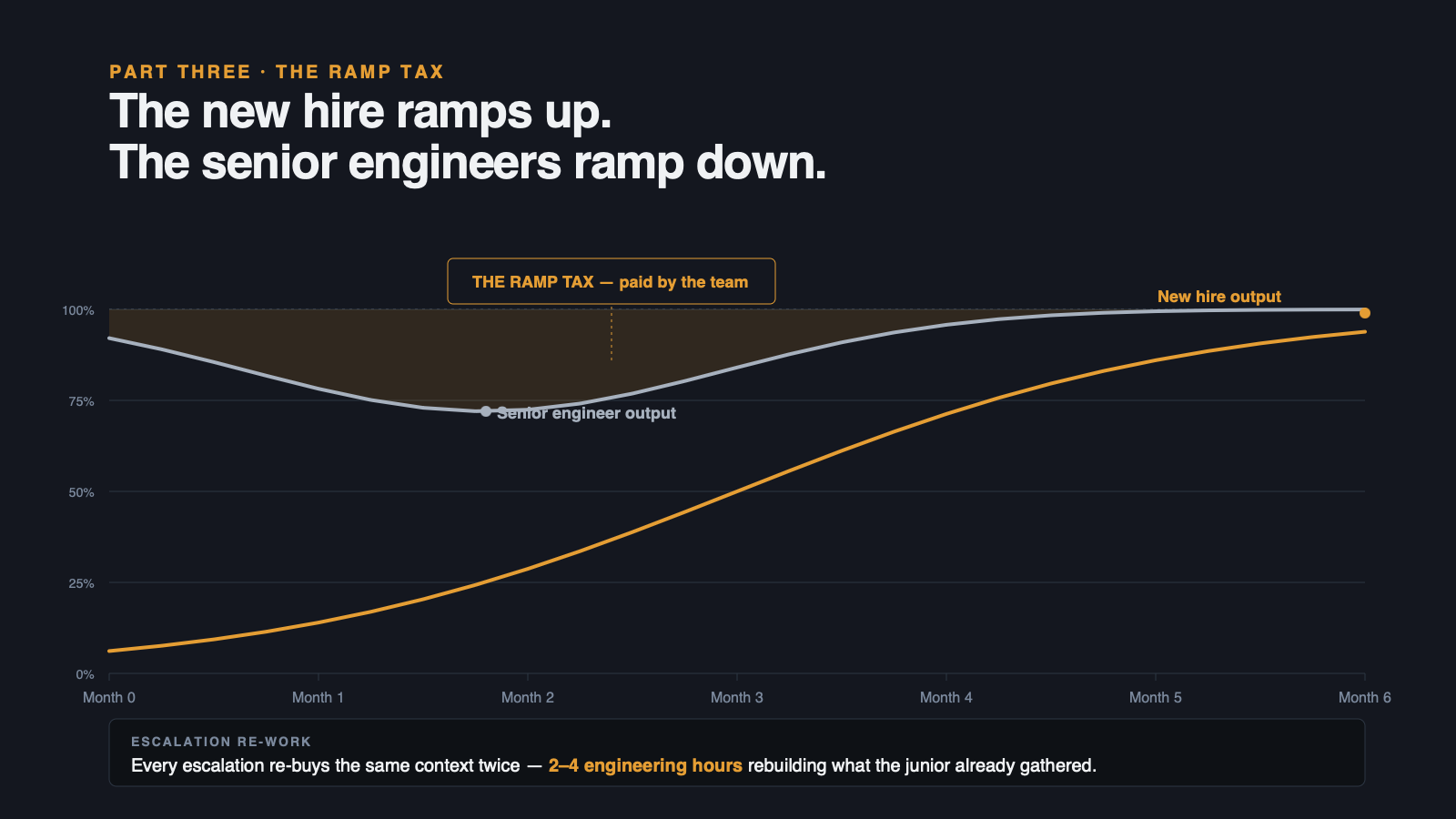
The standard model says a new support engineer is productive at month three. The reality is more uneven.
A startup founder on r/Startup_Ideas described scaling from 100 to 500 customers in four months while growing support from three to four engineers. They reduced new-hire ramp time from six weeks to ten days. That ramp compression is the outcome every leader wants. It is also rare enough to be a case study.
For most enterprise support organizations, ramp looks closer to the pattern we hear consistently from CS and engineering leaders: heavy reliance on peer transfer, oral handoff, and muscle memory. New engineers shadow senior engineers. They get unblocked by Slack. They learn the codebase the way humans always have, one debugging session at a time. Useful tickets resolved per week climbs over three to six months as pattern recognition builds.
During that window, the new engineer is not a productivity addition. They are a productivity tax on the senior engineers who answer their questions. Every "have you seen this before?" Slack ping pulls a senior engineer out of their own investigation. The team's effective capacity drops before it rises.
The escalation is where ramp pain compounds hardest. A junior engineer escalates to a senior. The senior reads the ticket, opens the same six tabs the junior just closed, and starts the investigation again from the beginning. Two to four engineering hours to reconstruct context that was already gathered once. Every escalation re-buys the same context twice.
Hiring adds engineers. It does not add the context that makes their investigations fast.
The two engineers keeping the lights on
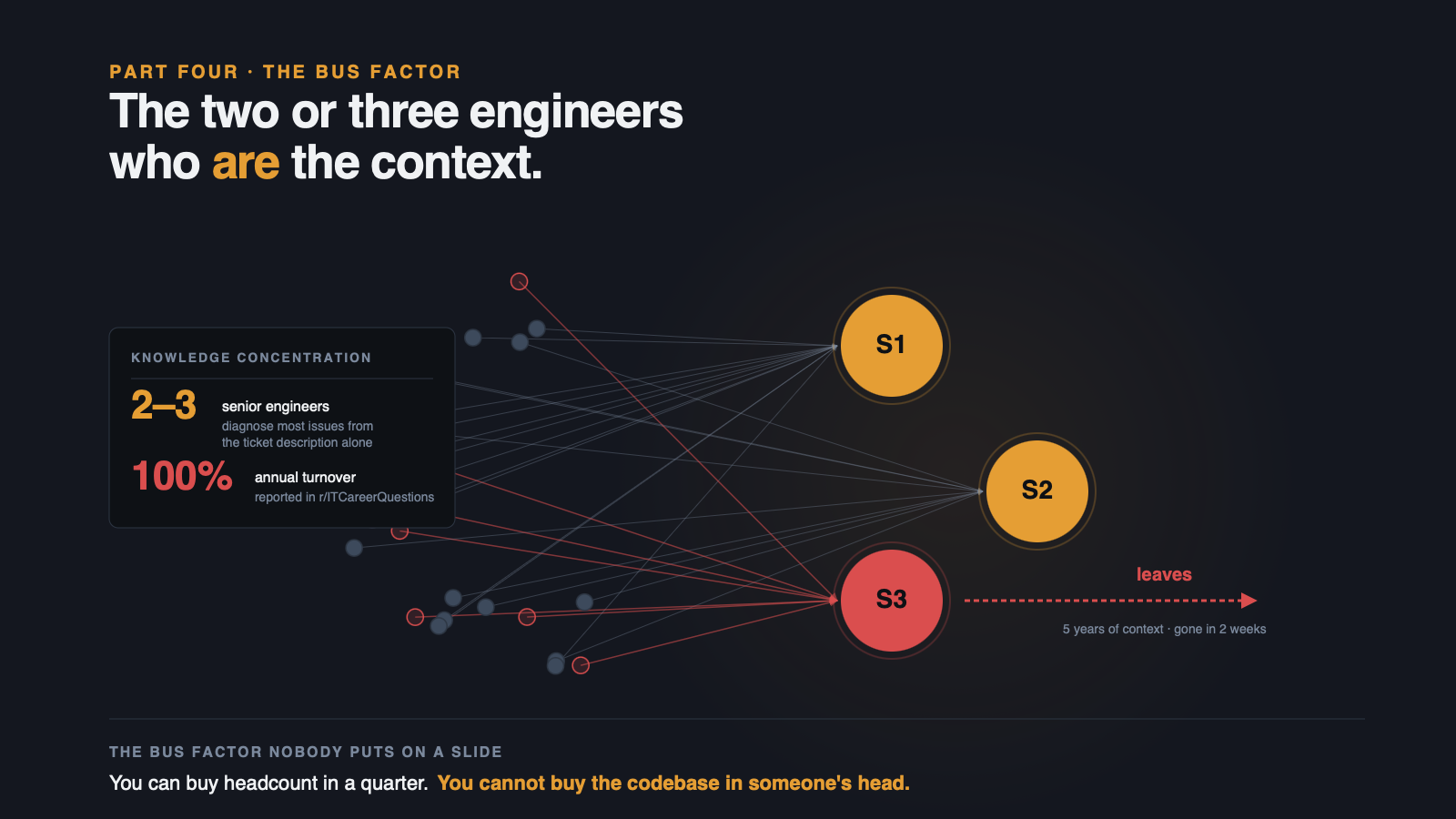
Every enterprise support organization has two or three senior engineers who can diagnose most issues from the ticket description alone. They have been there five years or longer. They have seen the codebase in production through dozens of incident cycles. They carry the failure modes in their heads.
They are the unacknowledged single points of failure.
The r/EngineeringManagers thread that produced the 15-of-48 measurement also described the corollary: "Senior engineers were informally on-call 24/7 because juniors didn't feel empowered to lead incidents." That is not a culture problem. It is a knowledge concentration problem. The juniors are not empowered because they do not yet have the context. The seniors stay on-call because they are the context.
Multiple Reddit threads in r/ITCareerQuestions describe 100% annual turnover in support engineering. The role is reactive. The career path is unclear. Performance metrics are tight. Burnout is structural. When one of the two or three senior engineers leaves, investigation time on the remaining team spikes. Not because the problems got harder. Because the knowledge walked out the door.
A VP Engineering can see this risk and still cannot solve it with hiring. The knowledge takes years to accumulate inside a single engineer. The recruiting market does not sell that. You can buy headcount in a quarter. You cannot buy the codebase in someone's head.
What scales instead
The mistake is treating investigation as a capacity problem. It is a knowledge problem.
The senior engineer who diagnoses an issue in 12 minutes knows something the junior does not. Not a technique. Not a skill that can be trained in a week. They have seen this failure mode before. They know which service touches the reconciliation flow because they fixed a similar issue last quarter. They know which log filter narrows the noise because they wrote it three months ago. That knowledge was built through hundreds of investigations. It lives in them.
Hiring adds engineers who have none of it. They have competence. They do not have the knowledge. It has to be rebuilt, one investigation at a time, from scratch. This is why ramp takes months, not weeks. And why it is not really a ramp problem. The knowledge exists inside the team. It is just not in any form the organization can use or transfer.
When one of those engineers leaves, the knowledge leaves with them.
What changes the shape of this problem is a system where investigation knowledge does not live only in people. Where the reasoning from ticket 1 is available to ticket 500. Where the code paths traced last quarter are part of the context for this quarter's escalation. Not because someone documented it. Documentation requires discipline and degrades. Because the investigation itself produced a record.
Enterprise software has always captured what changed. It rarely captured why it changed. Which hypotheses were ruled out. Which logs mattered. Which code path led to root cause. That reasoning is where investigation knowledge actually lives. And it disappears with every closed ticket.
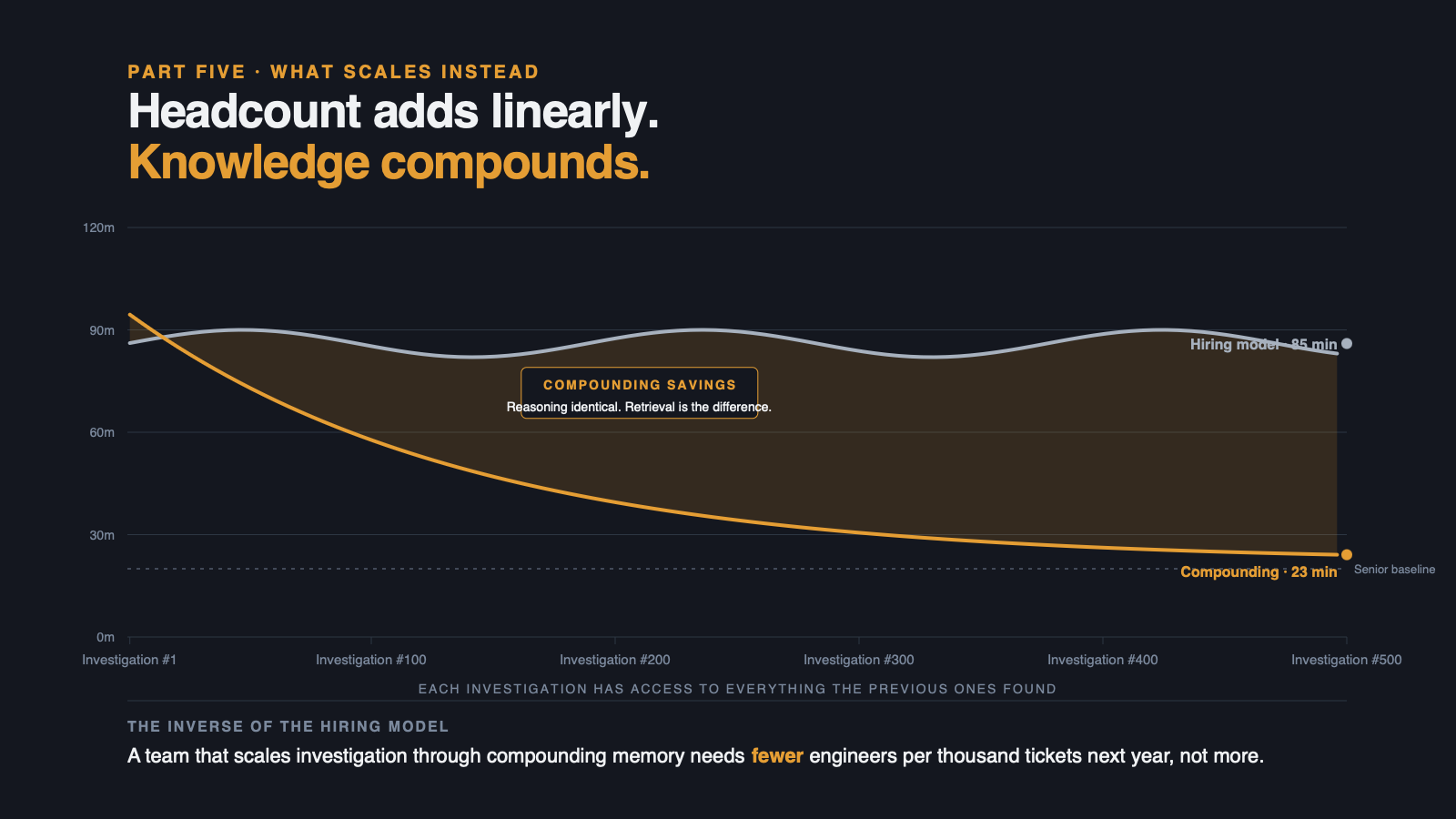
The 500th investigation on a codebase is structurally easier than the first. But only if the knowledge from the first 499 is somewhere the platform can use. Month 6 is measurably faster than Month 1 because the knowledge compounded. The engineers are doing the judgment. The platform carries the knowledge.
This is the inverse of the hiring model. Headcount adds linearly. Knowledge compounds. A team that scales through compounding investigation knowledge needs fewer engineers per thousand tickets next year than this year, not more.
What to ask before the next requisition

When the SLA-or-headcount conversation comes up next quarter, three questions sharpen the decision.
What percentage of resolution time is investigation versus fix? If the team has never measured it, that is the answer. Investigation is the line item nobody tracks because no dashboard reports it. Time it for a week on a representative sample of tickets. The number will almost certainly be above 60%.
What percentage of investigation time is new context versus context the team already gathered before? Pull ten tickets from the last quarter and check whether any of the investigation work was reproducible from prior tickets. If five of the ten could have been faster with access to a previous investigation's findings, the bottleneck is knowledge, not headcount.
Where would the next hire's first six months go? Onto ramping into investigation context that already exists inside the team, just not in a transferable form. That is what the hiring decision actually buys.
If any of those answers point at a knowledge problem rather than a capacity problem, the requisition is solving the wrong problem. Two more engineers will absorb the current ticket volume. They will not change the shape of the curve. The same conversation will repeat next quarter, with another hundred customers, against an SLA that scales linearly with growth.
The bet against this pattern is straightforward. The largest cost in support engineering is investigation. The largest source of investigation speed is institutional context. The institution that owns its context scales differently than the one that re-creates it per hire.
Calculate your Investigation Tax

The math takes about thirty seconds. Monthly ticket volume, multiplied by average investigation time per ticket, multiplied by your fully loaded engineer hourly rate. That is the annual cost of investigation work that does not compound.
Calculate your Investigation Tax →
For most mid-market SaaS organizations, the number is six figures annually. For enterprise organizations with 1,000 or more tickets a month, it is seven. None of it appears on a dashboard today.
More from the BuildWright team
View all posts →